優れたスキルは簡潔で、よく構造化されており、実際の使用でテストされています。このガイドは、Claudeが効果的にスキルを発見して使用できるスキルを作成するのに役立つ実践的な作成上の決定を提供します。
スキルの仕組みに関する概念的な背景については、スキル概要を参照してください。
コア原則
簡潔さが鍵
コンテキストウィンドウは公共の財産です。あなたのスキルは、Claudeが知る必要があるすべてのものとコンテキストウィンドウを共有します。これには以下が含まれます:
- システムプロンプト
- 会話履歴
- 他のスキルのメタデータ
- 実際のリクエスト
スキル内のすべてのトークンに直接的なコストがあるわけではありません。起動時には、すべてのスキルのメタデータ(名前と説明)のみが事前にロードされます。Claudeは、スキルが関連するようになったときにのみSKILL.mdを読み、必要に応じてのみ追加ファイルを読みます。ただし、SKILL.md内で簡潔であることは依然として重要です。Claudeがそれをロードすると、すべてのトークンが会話履歴と他のコンテキストと競合します。
デフォルトの仮定:Claudeはすでに非常に賢い
Claudeが既に持っていないコンテキストのみを追加してください。情報の各部分に異議を唱えてください:
- 「Claudeは本当にこの説明が必要ですか?」
- 「Claudeがこれを知っていると仮定できますか?」
- 「このパラグラフはそのトークンコストに見合う価値がありますか?」
良い例:簡潔 (約50トークン):
## PDFテキストの抽出
テキスト抽出にはpdfplumberを使用します:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## PDFテキストの抽出
PDF(ポータブルドキュメントフォーマット)ファイルは、テキスト、画像、その他のコンテンツを含む一般的なファイル形式です。PDFからテキストを抽出するには、ライブラリを使用する必要があります。PDF処理に利用可能なライブラリは多くありますが、使いやすく、ほとんどのケースに対応しているため、pdfplumberをお勧めします。まず、pipを使用してインストールする必要があります。その後、以下のコードを使用できます...
適切な自由度を設定する
タスクの脆弱性と可変性のレベルに特異性のレベルを合わせます。
高い自由度 (テキストベースの指示):
使用する場合:
- 複数のアプローチが有効
- 決定はコンテキストに依存
- ヒューリスティックがアプローチをガイド
例:
## コードレビュープロセス
1. コード構造と組織を分析する
2. 潜在的なバグやエッジケースをチェックする
3. 可読性と保守性の改善を提案する
4. プロジェクト規約への準拠を確認する
- 推奨パターンが存在する
- ある程度の変動が許容される
- 構成が動作に影響する
例:
## レポート生成
このテンプレートを使用して、必要に応じてカスタマイズしてください:
```python
def generate_report(data, format="markdown", include_charts=True):
# データを処理する
# 指定された形式で出力を生成する
# オプションで視覚化を含める
```
- 操作は脆弱でエラーが発生しやすい
- 一貫性が重要
- 特定のシーケンスに従う必要がある
例:
## データベースマイグレーション
このスクリプトを正確に実行してください:
```bash
python scripts/migrate.py --verify --backup
```
コマンドを変更したり、追加のフラグを追加したりしないでください。
- 両側に崖がある狭い橋:前に進む安全な方法は1つだけです。具体的なガードレールと正確な指示を提供してください(低い自由度)。例:正確なシーケンスで実行する必要があるデータベースマイグレーション。
- 危険のない開けた野原:多くのパスが成功につながります。一般的な方向を示し、Claudeが最適なルートを見つけることを信頼してください(高い自由度)。例:コンテキストが最適なアプローチを決定するコードレビュー。
使用予定のすべてのモデルでテストする
スキルはモデルへの追加として機能するため、効果は基礎となるモデルに依存します。使用予定のすべてのモデルでスキルをテストしてください。
モデル別のテスト考慮事項:
- Claude Haiku (高速、経済的):スキルは十分なガイダンスを提供していますか?
- Claude Sonnet (バランス型):スキルは明確で効率的ですか?
- Claude Opus (強力な推論):スキルは過度な説明を避けていますか?
Opusで完璧に機能するものは、Haikuではより詳細が必要な場合があります。複数のモデルでスキルを使用する予定がある場合は、すべてのモデルでうまく機能する指示を目指してください。
スキル構造
YAMLフロントマター:SKILL.mdフロントマターには2つのフィールドが必要です:name:
- 最大64文字
- 小文字、数字、ハイフンのみを含む必要があります
- XMLタグを含むことはできません
- 予約語を含むことはできません:「anthropic」、「claude」
description:
- 空でない必要があります
- 最大1024文字
- XMLタグを含むことはできません
- スキルが何をするか、いつ使用するかを説明する必要があります
完全なスキル構造の詳細については、スキル概要を参照してください。 命名規則
スキルを参照および議論しやすくするために、一貫した命名パターンを使用してください。スキル名には動名詞形 (動詞 + -ing)を使用することをお勧めします。これはスキルが提供するアクティビティまたは機能を明確に説明しているためです。
nameフィールドは小文字、数字、ハイフンのみを使用する必要があることに注意してください。
良い命名例 (動名詞形):
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codewriting-documentation
許容される代替案:
- 名詞句:
pdf-processing、spreadsheet-analysis
- アクション指向:
process-pdfs、analyze-spreadsheets
避けるべき:
- 曖昧な名前:
helper、utils、tools
- 過度に一般的:
documents、data、files
- 予約語:
anthropic-helper、claude-tools
- スキルコレクション内の一貫性のないパターン
一貫した命名により、以下が容易になります:
- ドキュメントと会話でスキルを参照する
- スキルが何をするかを一目で理解する
- 複数のスキルを整理して検索する
- プロフェッショナルで統一されたスキルライブラリを維持する
効果的な説明を書く
descriptionフィールドはスキル発見を有効にし、スキルが何をするか、いつ使用するかの両方を含める必要があります。
常に三人称で書いてください。説明はシステムプロンプトに挿入され、視点の不一致は発見の問題を引き起こす可能性があります。
- 良い:「Excelファイルを処理してレポートを生成します」
- 避ける:「Excelファイルの処理をお手伝いできます」
- 避ける:「これを使用してExcelファイルを処理できます」
description: PDFファイルからテキストと表を抽出し、フォームに入力し、ドキュメントをマージします。PDFファイル、フォーム、またはドキュメント抽出について言及している場合に使用してください。
description: Excelスプレッドシートを分析し、ピボットテーブルを作成し、グラフを生成します。Excelファイル、スプレッドシート、表形式データ、または.xlsxファイルを分析する場合に使用してください。
description: gitの差分を分析して、説明的なコミットメッセージを生成します。ユーザーがコミットメッセージの作成またはステージされた変更のレビューを支援するよう求めている場合に使用してください。
description: ドキュメントに役立ちます
description: ファイルでいろいろなことをします
段階的開示パターン
SKILL.mdは、オンボーディングガイドの目次のように、Claudeを詳細な資料に指し示す概要として機能します。段階的開示がどのように機能するかの説明については、概要のスキルの仕組みを参照してください。
実践的なガイダンス:
- SKILL.mdボディを最適なパフォーマンスのために500行以下に保つ
- この制限に近づいたときにコンテンツを別のファイルに分割する
- 以下のパターンを使用して、指示、コード、リソースを効果的に整理する
ビジュアル概要:シンプルから複雑へ
基本的なスキルは、メタデータと指示を含むSKILL.mdファイルのみで始まります:
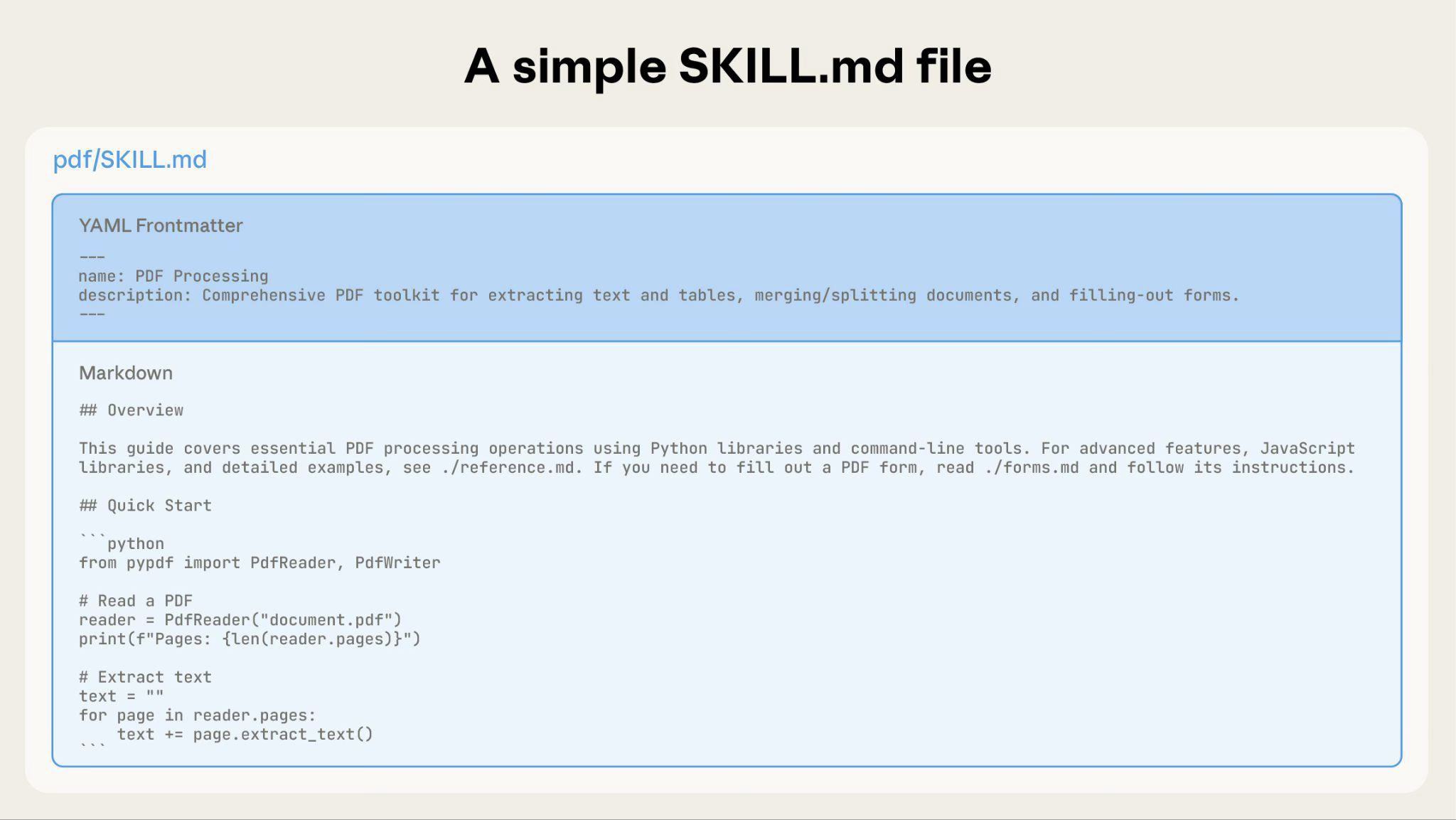 スキルが成長するにつれて、必要に応じてのみClaudeがロードする追加コンテンツをバンドルできます:
スキルが成長するにつれて、必要に応じてのみClaudeがロードする追加コンテンツをバンドルできます:
 完全なスキルディレクトリ構造は次のようになります:
完全なスキルディレクトリ構造は次のようになります:
pdf/
├── SKILL.md # メイン指示(トリガー時にロード)
├── FORMS.md # フォーム入力ガイド(必要に応じてロード)
├── reference.md # APIリファレンス(必要に応じてロード)
├── examples.md # 使用例(必要に応じてロード)
└── scripts/
├── analyze_form.py # ユーティリティスクリプト(実行、ロードなし)
├── fill_form.py # フォーム入力スクリプト
└── validate.py # 検証スクリプト
パターン1:参照付きの高レベルガイド
---
name: pdf-processing
description: PDFファイルからテキストと表を抽出し、フォームに入力し、ドキュメントをマージします。PDFファイル、フォーム、またはドキュメント抽出について言及している場合に使用してください。
---
# PDF処理
## クイックスタート
pdfplumberでテキストを抽出します:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## 高度な機能
**フォーム入力**:完全なガイドについては[FORMS.md](FORMS.md)を参照してください
**APIリファレンス**:すべてのメソッドについては[REFERENCE.md](REFERENCE.md)を参照してください
**例**:一般的なパターンについては[EXAMPLES.md](EXAMPLES.md)を参照してください
パターン2:ドメイン固有の組織
複数のドメインを持つスキルの場合、無関連なコンテキストのロードを避けるためにドメイン別にコンテンツを整理します。ユーザーが売上指標について尋ねる場合、Claudeは売上関連のスキーマのみを読む必要があり、財務またはマーケティングデータは不要です。これにより、トークン使用量が低く、コンテキストが焦点を当てたままになります。
bigquery-skill/
├── SKILL.md (概要とナビゲーション)
└── reference/
├── finance.md (収益、請求指標)
├── sales.md (機会、パイプライン)
├── product.md (API使用、機能)
└── marketing.md (キャンペーン、アトリビューション)
# BigQueryデータ分析
## 利用可能なデータセット
**財務**:収益、ARR、請求 → [reference/finance.md](reference/finance.md)を参照してください
**営業**:機会、パイプライン、アカウント → [reference/sales.md](reference/sales.md)を参照してください
**製品**:API使用、機能、採用 → [reference/product.md](reference/product.md)を参照してください
**マーケティング**:キャンペーン、アトリビューション、メール → [reference/marketing.md](reference/marketing.md)を参照してください
## クイック検索
grepを使用して特定のメトリクスを検索します:
```bash
grep -i "revenue" reference/finance.md
grep -i "pipeline" reference/sales.md
grep -i "api usage" reference/product.md
```
パターン3:条件付き詳細
基本的なコンテンツを表示し、高度なコンテンツにリンクします:
# DOCX処理
## ドキュメントの作成
新しいドキュメントにはdocx-jsを使用します。[DOCX-JS.md](DOCX-JS.md)を参照してください。
## ドキュメントの編集
簡単な編集の場合は、XMLを直接変更します。
**追跡変更の場合**:[REDLINING.md](REDLINING.md)を参照してください
**OOXML詳細の場合**:[OOXML.md](OOXML.md)を参照してください
深くネストされた参照を避ける
Claudeは、他の参照ファイルから参照されているファイルを部分的に読む場合があります。ネストされた参照に遭遇すると、Claudeはhead -100などのコマンドを使用してコンテンツをプレビューして、ファイル全体を読むのではなく、不完全な情報を得る可能性があります。
SKILL.mdから1レベル深い参照を保つ。すべての参照ファイルはSKILL.mdから直接リンクして、必要に応じてClaudeが完全なファイルを読むようにしてください。
悪い例:深すぎる:
# SKILL.md
[advanced.md](advanced.md)を参照してください...
# advanced.md
[details.md](details.md)を参照してください...
# details.md
実際の情報はここにあります...
# SKILL.md
**基本的な使用**:[SKILL.mdの指示]
**高度な機能**:[advanced.md](advanced.md)を参照してください
**APIリファレンス**:[reference.md](reference.md)を参照してください
**例**:[examples.md](examples.md)を参照してください
目次を使用して長い参照ファイルを構造化する
100行以上の参照ファイルの場合、上部に目次を含めます。これにより、部分的な読み取りでプレビューする場合でも、Claudeが利用可能な情報の完全な範囲を確認できます。
例:
# APIリファレンス
## 目次
- 認証とセットアップ
- コアメソッド(作成、読み取り、更新、削除)
- 高度な機能(バッチ操作、ウェブフック)
- エラー処理パターン
- コード例
## 認証とセットアップ
...
## コアメソッド
...
ワークフローとフィードバックループ
複雑なタスクにはワークフローを使用する
複雑な操作を明確で順序立ったステップに分割します。特に複雑なワークフローの場合は、Claudeが応答にコピーして進行状況をチェックできるチェックリストを提供します。
例1:研究統合ワークフロー (コードなしのスキル):
## 研究統合ワークフロー
このチェックリストをコピーして進行状況を追跡します:
```
研究進捗:
- [ ] ステップ1:すべてのソースドキュメントを読む
- [ ] ステップ2:主要なテーマを特定する
- [ ] ステップ3:クレームを相互参照する
- [ ] ステップ4:構造化された要約を作成する
- [ ] ステップ5:引用を確認する
```
**ステップ1:すべてのソースドキュメントを読む**
`sources/`ディレクトリ内の各ドキュメントを確認します。主な議論と支持する証拠をメモします。
**ステップ2:主要なテーマを特定する**
ソース全体のパターンを探します。どのテーマが繰り返し表示されますか?ソースはどこで同意または不同意ですか?
**ステップ3:クレームを相互参照する**
各主要なクレームについて、ソース資料に表示されることを確認します。各ポイントをサポートするソースをメモします。
**ステップ4:構造化された要約を作成する**
テーマ別に調査結果を整理します。以下を含めます:
- 主なクレーム
- ソースからの支持証拠
- 対立する見方(ある場合)
**ステップ5:引用を確認する**
すべてのクレームが正しいソースドキュメントを参照していることを確認します。引用が不完全な場合は、ステップ3に戻ります。
## PDFフォーム入力ワークフロー
このチェックリストをコピーして、完了時にアイテムをチェックします:
```
タスク進捗:
- [ ] ステップ1:フォームを分析する(analyze_form.pyを実行)
- [ ] ステップ2:フィールドマッピングを作成する(fields.jsonを編集)
- [ ] ステップ3:マッピングを検証する(validate_fields.pyを実行)
- [ ] ステップ4:フォームに入力する(fill_form.pyを実行)
- [ ] ステップ5:出力を確認する(verify_output.pyを実行)
```
**ステップ1:フォームを分析する**
実行:`python scripts/analyze_form.py input.pdf`
これはフォームフィールドとその場所を抽出し、`fields.json`に保存します。
**ステップ2:フィールドマッピングを作成する**
`fields.json`を編集して、各フィールドの値を追加します。
**ステップ3:マッピングを検証する**
実行:`python scripts/validate_fields.py fields.json`
続行する前に検証エラーを修正します。
**ステップ4:フォームに入力する**
実行:`python scripts/fill_form.py input.pdf fields.json output.pdf`
**ステップ5:出力を確認する**
実行:`python scripts/verify_output.py output.pdf`
検証が失敗した場合は、ステップ2に戻ります。
フィードバックループを実装する
一般的なパターン:バリデータを実行 → エラーを修正 → 繰り返す
このパターンは出力品質を大幅に改善します。
例1:スタイルガイド準拠 (コードなしのスキル):
## コンテンツレビュープロセス
1. STYLE_GUIDE.mdのガイドラインに従ってコンテンツを作成します
2. チェックリストに対してレビューします:
- 用語の一貫性を確認する
- 例が標準形式に従っていることを確認する
- すべての必須セクションが存在することを確認する
3. 問題が見つかった場合:
- 各問題を特定のセクション参照でメモする
- コンテンツを修正する
- チェックリストを再度レビューする
4. すべての要件が満たされたときのみ続行します
5. ドキュメントを最終化して保存します
## ドキュメント編集プロセス
1. `word/document.xml`に編集を加えます
2. **すぐに検証します**:`python ooxml/scripts/validate.py unpacked_dir/`
3. 検証が失敗した場合:
- エラーメッセージを注意深く確認する
- XMLの問題を修正する
- 検証を再度実行する
4. **検証が成功したときのみ続行します**
5. リビルド:`python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. 出力ドキュメントをテストします
コンテンツガイドライン
時間に敏感な情報を避ける
古くなる情報を含めないでください:
悪い例:時間に敏感 (間違いになります):
2025年8月前にこれを行っている場合は、古いAPIを使用してください。
2025年8月以降は、新しいAPIを使用してください。
## 現在の方法
v2 APIエンドポイントを使用します:`api.example.com/v2/messages`
## 古いパターン
<details>
<summary>レガシーv1 API(2025-08で廃止)</summary>
v1 APIは以下を使用していました:`api.example.com/v1/messages`
このエンドポイントはサポートされなくなりました。
</details>
一貫した用語を使用する
1つの用語を選択して、スキル全体で使用してください:
良い - 一貫性:
- 常に「APIエンドポイント」
- 常に「フィールド」
- 常に「抽出」
悪い - 一貫性がない:
- 「APIエンドポイント」、「URL」、「APIルート」、「パス」を混ぜる
- 「フィールド」、「ボックス」、「要素」、「コントロール」を混ぜる
- 「抽出」、「プル」、「取得」、「取り出す」を混ぜる
一貫性はClaudeが指示を理解して従うのに役立ちます。
一般的なパターン
テンプレートパターン
出力形式のテンプレートを提供します。厳密さのレベルをニーズに合わせます。
厳密な要件の場合 (APIレスポンスやデータ形式など):
## レポート構造
常にこの正確なテンプレート構造を使用してください:
```markdown
# [分析タイトル]
## エグゼクティブサマリー
[主要な調査結果の1段落の概要]
## 主要な調査結果
- サポートデータ付きの調査結果1
- サポートデータ付きの調査結果2
- サポートデータ付きの調査結果3
## 推奨事項
1. 具体的で実行可能な推奨事項
2. 具体的で実行可能な推奨事項
```
## レポート構造
これは合理的なデフォルト形式ですが、分析に基づいて最善の判断を使用してください:
```markdown
# [分析タイトル]
## エグゼクティブサマリー
[概要]
## 主要な調査結果
[発見に基づいてセクションを適応させる]
## 推奨事項
[特定のコンテキストに合わせてカスタマイズする]
```
特定の分析タイプに必要に応じてセクションを調整します。
例パターン
出力品質が例を見ることに依存するスキルの場合、通常のプロンプトと同じように入出力ペアを提供します:
## コミットメッセージ形式
これらの例に従ってコミットメッセージを生成します:
**例1:**
入力:JWTトークンを使用したユーザー認証を追加しました
出力:
```
feat(auth): JWT ベースの認証を実装する
ログインエンドポイントとトークン検証ミドルウェアを追加
```
**例2:**
入力:レポートで日付が正しく表示されないバグを修正しました
出力:
```
fix(reports): タイムゾーン変換での日付フォーマットを修正
レポート生成全体でUTCタイムスタンプを一貫して使用
```
**例3:**
入力:依存関係を更新し、エラー処理をリファクタリングしました
出力:
```
chore: 依存関係を更新してエラー処理をリファクタリング
- lodashを4.17.21にアップグレード
- エンドポイント全体でエラーレスポンス形式を標準化
```
このスタイルに従ってください:type(scope): 簡潔な説明、その後に詳細な説明。
条件付きワークフローパターン
Claudeを決定ポイントを通じてガイドします:
## ドキュメント変更ワークフロー
1. 変更タイプを決定します:
**新しいコンテンツを作成していますか?** → 以下の「作成ワークフロー」に従ってください
**既存のコンテンツを編集していますか?** → 以下の「編集ワークフロー」に従ってください
2. 作成ワークフロー:
- docx-jsライブラリを使用する
- 最初からドキュメントを構築する
- .docx形式にエクスポートする
3. 編集ワークフロー:
- 既存のドキュメントを解凍する
- XMLを直接変更する
- 各変更後に検証する
- 完了時に再パックする
ワークフローが多くのステップで大きくまたは複雑になった場合は、それらを別のファイルに移動し、タスクに基づいて適切なファイルを読むようにClaudeに指示することを検討してください。
評価と反復
最初に評価を構築する
広範なドキュメントを作成する前に評価を作成してください。 これにより、スキルが想像上の問題ではなく実際の問題を解決することを確認します。
評価駆動開発:
- ギャップを特定する:スキルなしで代表的なタスクでClaudeを実行します。具体的な失敗または欠落しているコンテキストを文書化します
- 評価を作成する:これらのギャップをテストする3つのシナリオを構築します
- ベースラインを確立する:スキルなしでClaudeのパフォーマンスを測定します
- 最小限の指示を書く:ギャップに対処して評価に合格するのに十分なコンテンツのみを作成します
- 反復する:評価を実行し、ベースラインと比較し、改善します
このアプローチにより、実現しない可能性のある要件を予測するのではなく、実際の問題を解決していることを確認します。
評価構造:
{
"skills": ["pdf-processing"],
"query": "このPDFファイルからすべてのテキストを抽出し、output.txtに保存します",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"適切なPDF処理ライブラリまたはコマンドラインツールを使用してPDFファイルを正常に読み取ります",
"ドキュメント内のすべてのページからテキストコンテンツを抽出し、ページを逃しません",
"抽出されたテキストを明確で読みやすい形式でoutput.txtという名前のファイルに保存します"
]
}
この例は、シンプルなテストルーブリックを使用したデータ駆動型評価を示しています。現在、これらの評価を実行するための組み込み方法は提供していません。ユーザーは独自の評価システムを作成できます。評価はスキル効果を測定するための真実の源です。
Claudeを使用してスキルを反復的に開発する
最も効果的なスキル開発プロセスはClaudeそのものを含みます。1つのClaudeインスタンス(「Claude A」)と協力してスキルを作成し、他のインスタンス(「Claude B」)で使用します。Claude Aは指示の設計と改善を支援し、Claude Bは実際のタスクでそれらをテストします。これが機能するのは、Claudeモデルが効果的なエージェント指示を書く方法とエージェントが必要とする情報の両方を理解しているためです。
新しいスキルの作成:
-
スキルなしでタスクを完了する:Claude Aと通常のプロンプトを使用して問題を解決します。作業を進めるにつれて、自然にコンテキストを提供し、設定を説明し、手続き知識を共有します。繰り返し提供する情報に注意してください。
-
再利用可能なパターンを特定する:タスクを完了した後、使用したコンテキストを特定し、それが同様の将来のタスクに役立つでしょう。
例:BigQuery分析を実行した場合、テーブル名、フィールド定義、フィルタリングルール(「常にテストアカウントを除外」など)、および一般的なクエリパターンを提供した可能性があります。
-
Claude Aにスキルを作成するよう依頼する:「このBigQuery分析パターンをキャプチャするスキルを作成してください。テーブルスキーマ、命名規則、テストアカウントのフィルタリングに関するルールを含めてください。」
Claudeモデルはスキル形式と構造をネイティブに理解しています。スキルを作成するようにClaudeに依頼するには、特別なシステムプロンプトや「スキル作成」スキルは必要ありません。Claudeにスキルを作成するよう依頼すると、適切なフロントマターとボディコンテンツを含む適切に構造化されたSKILL.mdコンテンツが生成されます。
-
簡潔性をレビューする:Claude Aが不要な説明を追加していないかチェックしてください。「Claudeが既に知っているため、勝率が何を意味するかについての説明を削除してください」と尋ねます。
-
情報アーキテクチャを改善する:Claude Aにコンテンツをより効果的に整理するよう依頼します。例えば:「テーブルスキーマを別の参照ファイルに整理してください。後で更にテーブルを追加する可能性があります。」
-
同様のタスクでテストする:Claude B(スキルがロードされた新しいインスタンス)で関連するユースケースでスキルを使用します。Claude Bが正しい情報を見つけ、ルールを正しく適用し、タスクを正常に処理するかどうかを観察します。
-
観察に基づいて反復する:Claude Bが苦労したり何かを逃したりした場合、具体的な情報を持ってClaudeAに戻ります:「Claudeがこのスキルを使用したとき、Q4の日付でフィルタリングするのを忘れました。日付フィルタリングパターンに関するセクションを追加する必要がありますか?」
既存のスキルを反復する:
同じ階層的パターンは、スキルを改善するときに続きます。以下の間で交互に行います:
- Claude Aと協力する (スキルの改善を支援する専門家)
- Claude Bでテストする (スキルを使用して実際の作業を実行するエージェント)
- Claude Bの動作を観察する し、Claude Aに洞察をもたらします
-
実際のワークフローでスキルを使用する:テストシナリオではなく、Claude B(スキルがロードされた)に実際のタスクを提供します
-
Claude Bの動作を観察する:苦労する場所、成功する場所、または予期しない選択をする場所をメモします
観察例:「Claude Bに地域別売上レポートを求めたとき、クエリを作成しましたが、スキルがこのルールについて言及しているにもかかわらず、テストアカウントをフィルタリングするのを忘れました。」
-
改善のためにClaudeAに戻る:現在のSKILL.mdを共有し、観察したことを説明します。「Claude Bがテストアカウントをフィルタリングするのを忘れたことに気付きました。スキルはフィルタリングについて言及していますが、十分に目立たないかもしれません。」
-
Claude Aの提案をレビューする:Claude Aは、「常にフィルタリング」の代わりに「MUSTフィルタリング」を使用するなど、ルールをより目立たせるために再整理することを提案するか、ワークフローセクションを再構成することを提案するかもしれません。
-
変更を適用してテストする:Claude Aの改善でスキルを更新し、同様のリクエストでClaudeBで再度テストします
-
使用に基づいて繰り返す:新しいシナリオに遭遇するにつれてこの観察-改善-テストサイクルを続けます。各反復は、仮定ではなく観察されたエージェント動作に基づいてスキルを改善します。
チームフィードバックの収集:
- スキルをチームメイトと共有し、使用を観察します
- 尋ねます:スキルは予期したときにアクティブになりますか?指示は明確ですか?何が不足していますか?
- フィードバックを組み込んで、独自の使用パターンの盲点に対処します
このアプローチが機能する理由:Claude Aはエージェントのニーズを理解し、あなたはドメイン専門知識を提供し、Claude Bは実際の使用を通じてギャップを明らかにし、反復的な改善は仮定ではなく観察された動作に基づいてスキルを改善します。
Claudeがスキルをナビゲートする方法を観察する
スキルを反復するにつれて、Claudeが実際に使用する方法に注意を払ってください。以下を監視します:
- 予期しない探索パス:Claudeは予期しない順序でファイルを読みますか?これは、構造が考えたほど直感的ではないことを示す可能性があります
- 接続の欠落:Claudeは重要なファイルへの参照に従うのに失敗しますか?リンクはより明示的または目立つ必要があるかもしれません
- 特定のセクションへの過度な依存:Claudeが繰り返し同じファイルを読む場合、そのコンテンツはメインのSKILL.mdの代わりに配置する必要があるかもしれません
- 無視されたコンテンツ:Claudeがバンドルされたファイルにアクセスしない場合、それは不要であるか、メイン指示で不十分に通知されている可能性があります
仮定ではなく、これらの観察に基づいて反復します。スキルのメタデータの「name」と「description」は特に重要です。Claudeはこれらを使用して、現在のタスクに応じてスキルをトリガーするかどうかを決定します。スキルが何をするか、いつ使用すべきかを明確に説明していることを確認してください。
避けるべきアンチパターン
Windowsスタイルのパスを避ける
Windowsでも常にフォワードスラッシュをファイルパスで使用してください:
- ✓ 良い:
scripts/helper.py、reference/guide.md
- ✗ 避ける:
scripts\helper.py、reference\guide.md
Unixスタイルのパスはすべてのプラットフォームで機能しますが、WindowsスタイルのパスはUnixシステムでエラーを引き起こします。
多くのオプションを提供しすぎることを避ける
必要でない限り、複数のアプローチを提示しないでください:
**悪い例:選択肢が多すぎる** (混乱を招く):
「pypdfまたはpdfplumberまたはPyMuPDFまたはpdf2imageまたは...を使用できます」
**良い例:デフォルトを提供する** (逃げ道付き):
「テキスト抽出にはpdfplumberを使用してください:
```python
import pdfplumber
```
スキャンされたPDFでOCRが必要な場合は、代わりにpdf2imageとpytesseractを使用してください。」
高度:実行可能なコード付きスキル
以下のセクションは、実行可能なスクリプトを含むスキルに焦点を当てています。スキルがマークダウン指示のみを使用する場合は、効果的なスキルのチェックリストにスキップしてください。
解決する、逃げ出さない
スキル用のスクリプトを作成するときは、Claudeに任せるのではなくエラー条件を処理してください。
良い例:エラーを明示的に処理する:
def process_file(path):
"""ファイルを処理し、存在しない場合は作成します。"""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# 失敗する代わりにデフォルトコンテンツでファイルを作成する
print(f"ファイル{path}が見つかりません、デフォルトを作成しています")
with open(path, 'w') as f:
f.write('')
return ''
except PermissionError:
# 失敗する代わりに代替案を提供する
print(f"{path}にアクセスできません、デフォルトを使用しています")
return ''
def process_file(path):
# 失敗して、Claudeに理解させる
return open(path).read()
# HTTPリクエストは通常30秒以内に完了します
# より長いタイムアウトは遅い接続を考慮します
REQUEST_TIMEOUT = 30
# 3回の再試行は信頼性と速度のバランスを取ります
# ほとんどの一時的な失敗は2回目の再試行で解決します
MAX_RETRIES = 3
TIMEOUT = 47 # なぜ47?
RETRIES = 5 # なぜ5?
ユーティリティスクリプトを提供する
Claudeがスクリプトを書くことができたとしても、事前に作成されたスクリプトには利点があります:
ユーティリティスクリプトの利点:
- 生成されたコードより信頼性が高い
- トークンを節約する(コンテキストにコードを含める必要がない)
- 時間を節約する(コード生成は不要)
- 使用全体で一貫性を確保する
 上の図は、実行可能なスクリプトが指示ファイルとどのように連携するかを示しています。指示ファイル(forms.md)はスクリプトを参照し、Claudeはコンテンツをコンテキストにロードせずに実行できます。
重要な区別:指示で明確にしてください。Claudeは以下のどちらを行うべきですか:
上の図は、実行可能なスクリプトが指示ファイルとどのように連携するかを示しています。指示ファイル(forms.md)はスクリプトを参照し、Claudeはコンテンツをコンテキストにロードせずに実行できます。
重要な区別:指示で明確にしてください。Claudeは以下のどちらを行うべきですか:
- スクリプトを実行する (最も一般的):「analyze_form.pyを実行してフィールドを抽出する」
- 参照として読む (複雑なロジックの場合):「フィールド抽出アルゴリズムについてはanalyze_form.pyを参照してください」
ほとんどのユーティリティスクリプトでは、実行がより信頼性が高く効率的であるため、実行が推奨されます。スクリプト実行がどのように機能するかの詳細については、以下のランタイム環境セクションを参照してください。
例:
## ユーティリティスクリプト
**analyze_form.py**:PDFからすべてのフォームフィールドを抽出
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
出力形式:
```json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
```
**validate_boxes.py**:重複する境界ボックスをチェック
```bash
python scripts/validate_boxes.py fields.json
# 戻り値:「OK」または競合をリスト
```
**fill_form.py**:フィールド値をPDFに適用
```bash
python scripts/fill_form.py input.pdf fields.json output.pdf
```
ビジュアル分析を使用する
入力を画像としてレンダリングできる場合、Claudeに分析させます:
## フォームレイアウト分析
1. PDFを画像に変換します:
```bash
python scripts/pdf_to_images.py form.pdf
```
2. 各ページ画像を分析してフォームフィールドを特定する
3. Claudeはフィールドの場所とタイプを視覚的に確認できます
この例では、pdf_to_images.pyスクリプトを作成する必要があります。
検証可能な中間出力を作成する
Claudeが複雑でオープンエンドのタスクを実行する場合、間違いを犯す可能性があります。「計画-検証-実行」パターンは、Claudeが最初に構造化形式で計画を作成し、その計画を実行する前にスクリプトで検証することで、早期にエラーをキャッチします。
例:スプレッドシートに基づいてPDFの50個のフォームフィールドを更新するようにClaudeに依頼することを想像してください。検証がなければ、Claudeは存在しないフィールドを参照し、競合する値を作成し、必須フィールドを逃し、または更新を誤って適用する可能性があります。
解決策:上記のワークフローパターンを使用しますが、変更を適用する前に検証される中間changes.jsonファイルを追加します。ワークフローは以下になります:分析 → 計画ファイルを作成 → 計画を検証 → 実行 → 確認。
このパターンが機能する理由:
- 早期にエラーをキャッチする:検証は変更を適用する前に問題を見つけます
- 機械検証可能:スクリプトは客観的な検証を提供します
- 可逆的な計画:Claudeは元のファイルに触れずに計画を反復できます
- 明確なデバッグ:エラーメッセージは特定の問題を指します
使用する場合:バッチ操作、破壊的な変更、複雑な検証ルール、高リスク操作。
実装のヒント:「フィールド’signature_date’が見つかりません。利用可能なフィールド:customer_name、order_total、signature_date_signed」のような特定のエラーメッセージを使用して検証スクリプトを詳細にして、Claudeが問題を修正するのに役立てます。
パッケージ依存関係
スキルはコード実行環境で実行され、プラットフォーム固有の制限があります:
- claude.ai:npmとPyPiからパッケージをインストールでき、GitHubリポジトリからプルできます
- Anthropic API:ネットワークアクセスがなく、ランタイムパッケージのインストールがありません
SKILL.mdで必要なパッケージをリストし、コード実行ツールドキュメントで利用可能であることを確認してください。
ランタイム環境
スキルはファイルシステムアクセス、bashコマンド、およびコード実行機能を備えたコード実行環境で実行されます。このアーキテクチャの概念的な説明については、概要のスキルアーキテクチャを参照してください。
これが作成に与える影響:
Claudeがスキルにアクセスする方法:
- メタデータ事前ロード:起動時に、すべてのスキルのYAMLフロントマターからの名前と説明がシステムプロンプトにロードされます
- オンデマンドでファイルを読む:Claudeは必要に応じてbash読み取りツールを使用してファイルシステムからSKILL.mdおよび他のファイルにアクセスします
- スクリプトを効率的に実行:ユーティリティスクリプトは完全なコンテンツをコンテキストにロードせずにbashを介して実行できます。スクリプトの出力のみがトークンを消費します
- 大きなファイルのコンテキストペナルティなし:参照ファイル、データ、またはドキュメントは、実際に読まれるまでコンテキストトークンを消費しません
- ファイルパスが重要:Claudeはファイルシステムのようにスキルディレクトリをナビゲートします。フォワードスラッシュ(
reference/guide.md)を使用し、バックスラッシュは使用しないでください
- ファイルに説明的な名前を付ける:コンテンツを示す名前を使用します:
form_validation_rules.md、doc2.mdではなく
- 発見のために整理する:ドメインまたは機能別にディレクトリを構造化します
- 良い:
reference/finance.md、reference/sales.md
- 悪い:
docs/file1.md、docs/file2.md
- 包括的なリソースをバンドルする:完全なAPIドキュメント、広範な例、大規模なデータセットを含めます。アクセスされるまでコンテキストペナルティはありません
- 決定論的操作にはスクリプトを優先する:Claudeにコード生成を求めるのではなく
validate_form.pyを作成してください
- 実行意図を明確にする:
- 「analyze_form.pyを実行してフィールドを抽出する」(実行)
- 「抽出アルゴリズムについてはanalyze_form.pyを参照してください」(参照として読む)
- ファイルアクセスパターンをテストする:実際のリクエストでテストして、Claudeがディレクトリ構造をナビゲートできることを確認します
例:
bigquery-skill/
├── SKILL.md (概要、参照ファイルを指す)
└── reference/
├── finance.md (収益指標)
├── sales.md (パイプラインデータ)
└── product.md (使用分析)
reference/finance.mdへの参照を見て、bashを呼び出してそのファイルのみを読みます。sales.mdとproduct.mdファイルはファイルシステムに残り、必要になるまでゼロコンテキストトークンを消費します。このファイルシステムベースのモデルが段階的開示を有効にするものです。Claudeは各タスクが必要とするものを正確にナビゲートして選択的にロードできます。
完全な技術アーキテクチャの詳細については、スキル概要のスキルの仕組みを参照してください。
MCPツール参照
スキルがMCP(モデルコンテキストプロトコル)ツールを使用する場合、「ツールが見つかりません」エラーを避けるために常に完全修飾ツール名を使用してください。
形式:ServerName:tool_name
例:
BigQuery:bigquery_schemaツールを使用してテーブルスキーマを取得します。
GitHub:create_issueツールを使用して問題を作成します。
BigQueryとGitHubはMCPサーバー名ですbigquery_schemaとcreate_issueはそれらのサーバー内のツール名です
サーバープレフィックスがないと、特に複数のMCPサーバーが利用可能な場合、Claudeはツールの場所を特定できない可能性があります。
ツールがインストールされていると仮定しないでください
パッケージが利用可能であると仮定しないでください:
**悪い例:インストールを仮定**:
「pdfライブラリを使用してファイルを処理します。」
**良い例:依存関係について明示的**:
「必要なパッケージをインストールします:`pip install pypdf`
その後、それを使用します:
```python
from pypdf import PdfReader
reader = PdfReader("file.pdf")
```"
技術的な注記
YAMLフロントマター要件
SKILL.mdフロントマターには、特定の検証ルールを持つnameとdescriptionフィールドが必要です:
name:最大64文字、小文字/数字/ハイフンのみ、XMLタグなし、予約語なしdescription:最大1024文字、空でない、XMLタグなし
完全な構造の詳細については、スキル概要を参照してください。
トークン予算
最適なパフォーマンスのためにSKILL.mdボディを500行以下に保ちます。コンテンツがこれを超える場合は、前述の段階的開示パターンを使用して別のファイルに分割します。アーキテクチャの詳細については、スキル概要を参照してください。
効果的なスキルのチェックリスト
スキルを共有する前に、以下を確認してください:
コア品質
コードとスクリプト
テスト
次のステップ