Choosing a model
We recommend using the latest Claude Sonnet (4.5) or Claude Opus (4.1) model for complex tools and ambiguous queries; they handle multiple tools better and seek clarification when needed. Use Claude Haiku models for straightforward tools, but note they may infer missing parameters.Specifying client tools
Client tools (both Anthropic-defined and user-defined) are specified in thetools top-level parameter of the API request. Each tool definition includes:
| Parameter | Description |
|---|---|
name | The name of the tool. Must match the regex ^[a-zA-Z0-9_-]{1,64}$. |
description | A detailed plaintext description of what the tool does, when it should be used, and how it behaves. |
input_schema | A JSON Schema object defining the expected parameters for the tool. |
Example simple tool definition
Example simple tool definition
JSON
get_weather, expects an input object with a required location string and an optional unit string that must be either “celsius” or “fahrenheit”.Tool use system prompt
When you call the Claude API with thetools parameter, we construct a special system prompt from the tool definitions, tool configuration, and any user-specified system prompt. The constructed prompt is designed to instruct the model to use the specified tool(s) and provide the necessary context for the tool to operate properly:
Best practices for tool definitions
To get the best performance out of Claude when using tools, follow these guidelines:- Provide extremely detailed descriptions. This is by far the most important factor in tool performance. Your descriptions should explain every detail about the tool, including:
- What the tool does
- When it should be used (and when it shouldn’t)
- What each parameter means and how it affects the tool’s behavior
- Any important caveats or limitations, such as what information the tool does not return if the tool name is unclear. The more context you can give Claude about your tools, the better it will be at deciding when and how to use them. Aim for at least 3-4 sentences per tool description, more if the tool is complex.
- Prioritize descriptions over examples. While you can include examples of how to use a tool in its description or in the accompanying prompt, this is less important than having a clear and comprehensive explanation of the tool’s purpose and parameters. Only add examples after you’ve fully fleshed out the description.
Example of a good tool description
Example of a good tool description
JSON
Example poor tool description
Example poor tool description
JSON
ticker parameter means. The poor description is too brief and leaves Claude with many open questions about the tool’s behavior and usage.
Tool runner (beta)
The tool runner provides an out-of-the-box solution for executing tools with Claude. Instead of manually handling tool calls, tool results, and conversation management, the tool runner automatically:- Executes tools when Claude calls them
- Handles the request/response cycle
- Manages conversation state
- Provides type safety and validation
The tool runner is currently in beta and only available in the Python and TypeScript SDKs.
- Python
- TypeScript (Zod)
- TypeScript (JSON Schema)
Basic usage
Use the@beta_tool decorator to define tools and client.beta.messages.tool_runner() to execute them.If you’re using the async client, replace
@beta_tool with @beta_async_tool and define the function with async def.@beta_tool decorator will inspect the function arguments and the docstring to extract a json schema representation of the given function, in the example above calculate_sum will be turned into:Iterating over the tool runner
The tool runner returned bytool_runner() is an iterable, which you can iterate over with a for loop. This is often referred to as a “tool call loop”.
Each loop iteration yields a message that was returned by Claude.After your code has a chance to process the current message inside the loop, the tool runner will check the message to see if Claude requested a tool use. If so, it will call the tool and send the tool result back to Claude automatically, then yield the next message from Claude to start the next iteration of your loop.You may end the loop at any iteration with a simple break statement. The tool runner will loop until Claude returns a message without a tool use.If you don’t care about intermediate messages, instead of using a loop, you can call the until_done() method, which will return the final message from Claude:Advanced usage
Within the loop, you have the ability to fully customize the tool runner’s next request to the Messages API. The methodrunner.generate_tool_call_response() will call the tool (if Claude triggered a tool use) and give you access to the tool result that will be sent back to the Messages API.
The methods runner.set_messages_params() and runner.append_messages() allow you to modify the parameters for the next Messages API request.Streaming
When enabling streaming withstream=True, each value emitted by the tool runner is a BetaMessageStream as returned from anthropic.messages.stream(). The BetaMessageStream is itself an iterable that yields streaming events from the Messages API.You can use message_stream.get_final_message() to let the SDK do the accumulation of streaming events into the final message for you.The SDK tool runner is in beta. The rest of this document covers manual tool implementation.
Controlling Claude’s output
Forcing tool use
In some cases, you may want Claude to use a specific tool to answer the user’s question, even if Claude thinks it can provide an answer without using a tool. You can do this by specifying the tool in thetool_choice field like so:
autoallows Claude to decide whether to call any provided tools or not. This is the default value whentoolsare provided.anytells Claude that it must use one of the provided tools, but doesn’t force a particular tool.toolallows us to force Claude to always use a particular tool.noneprevents Claude from using any tools. This is the default value when notoolsare provided.
When using prompt caching, changes to the
tool_choice parameter will invalidate cached message blocks. Tool definitions and system prompts remain cached, but message content must be reprocessed.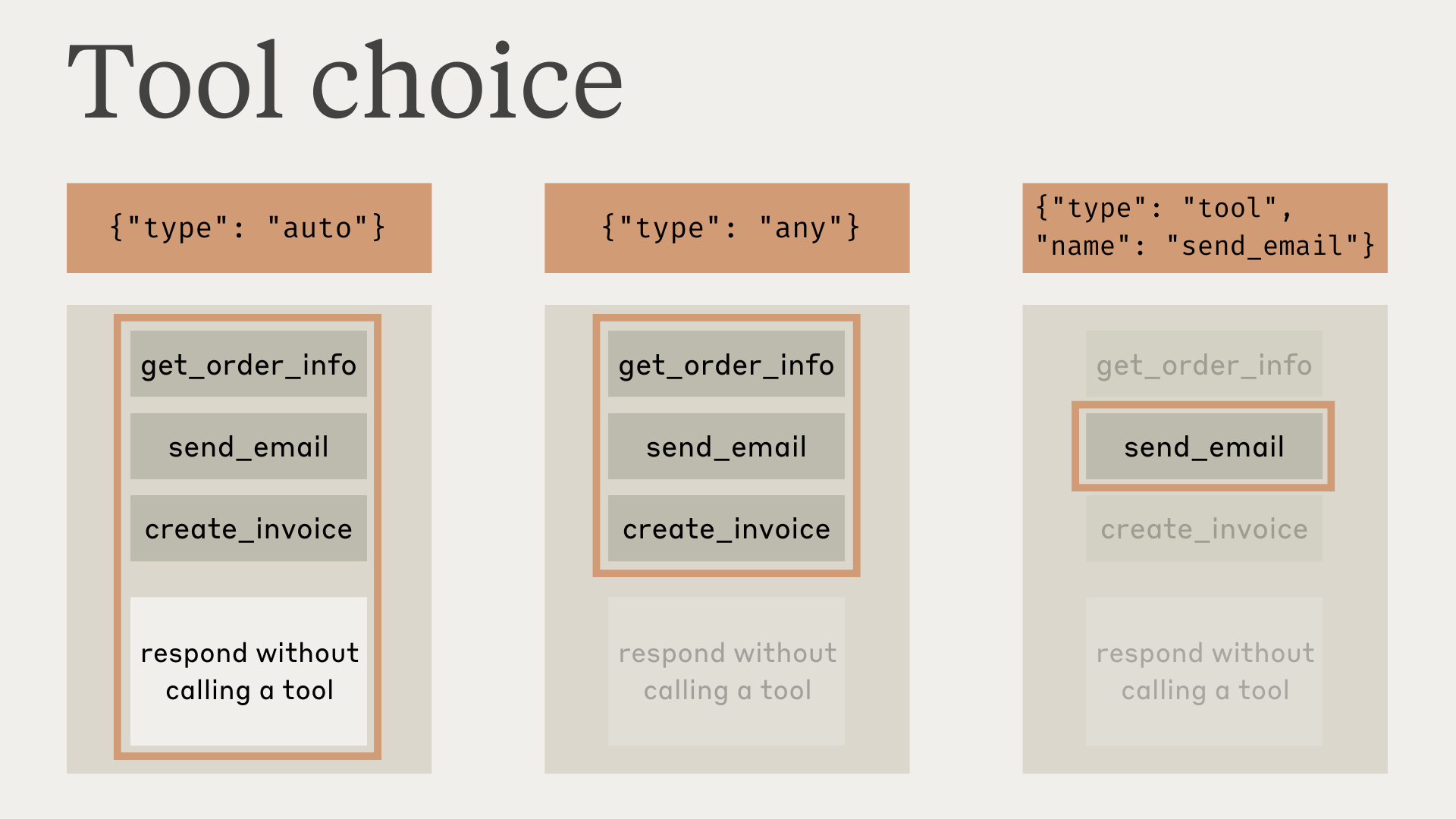
tool_choice as any or tool, we will prefill the assistant message to force a tool to be used. This means that the models will not emit a natural language response or explanation before tool_use content blocks, even if explicitly asked to do so.
When using extended thinking with tool use,
tool_choice: {"type": "any"} and tool_choice: {"type": "tool", "name": "..."} are not supported and will result in an error. Only tool_choice: {"type": "auto"} (the default) and tool_choice: {"type": "none"} are compatible with extended thinking.{"type": "auto"} for tool_choice (the default) and add explicit instructions in a user message. For example: What's the weather like in London? Use the get_weather tool in your response.
JSON output
Tools do not necessarily need to be client functions — you can use tools anytime you want the model to return JSON output that follows a provided schema. For example, you might use arecord_summary tool with a particular schema. See Tool use with Claude for a full working example.
Model responses with tools
When using tools, Claude will often comment on what it’s doing or respond naturally to the user before invoking tools. For example, given the prompt “What’s the weather like in San Francisco right now, and what time is it there?”, Claude might respond with:JSON
<examples> in your prompts.
It’s important to note that Claude may use various phrasings and approaches when explaining its actions. Your code should treat these responses like any other assistant-generated text, and not rely on specific formatting conventions.
Parallel tool use
By default, Claude may use multiple tools to answer a user query. You can disable this behavior by:- Setting
disable_parallel_tool_use=truewhen tool_choice type isauto, which ensures that Claude uses at most one tool - Setting
disable_parallel_tool_use=truewhen tool_choice type isanyortool, which ensures that Claude uses exactly one tool
Complete parallel tool use example
Complete parallel tool use example
Simpler with Tool runner: The example below shows manual parallel tool handling. For most use cases, tool runner automatically handle parallel tool execution with much less code.
Complete test script for parallel tools
Complete test script for parallel tools
Here’s a complete, runnable script to test and verify parallel tool calls are working correctly:This script demonstrates:
- How to properly format parallel tool calls and results
- How to verify that parallel calls are being made
- The correct message structure that encourages future parallel tool use
- Common mistakes to avoid (like text before tool results)
Maximizing parallel tool use
While Claude 4 models have excellent parallel tool use capabilities by default, you can increase the likelihood of parallel tool execution across all models with targeted prompting:System prompts for parallel tool use
System prompts for parallel tool use
For Claude 4 models (Opus 4.1, Opus 4, and Sonnet 4), add this to your system prompt:For even stronger parallel tool use (recommended if the default isn’t sufficient), use:
User message prompting
User message prompting
You can also encourage parallel tool use within specific user messages:
Handling tool use and tool result content blocks
Simpler with Tool runner: The manual tool handling described in this section is automatically managed by tool runner. Use this section when you need custom control over tool execution.
Handling results from client tools
The response will have astop_reason of tool_use and one or more tool_use content blocks that include:
id: A unique identifier for this particular tool use block. This will be used to match up the tool results later.name: The name of the tool being used.input: An object containing the input being passed to the tool, conforming to the tool’sinput_schema.
Example API response with a `tool_use` content block
Example API response with a `tool_use` content block
JSON
- Extract the
name,id, andinputfrom thetool_useblock. - Run the actual tool in your codebase corresponding to that tool name, passing in the tool
input. - Continue the conversation by sending a new message with the
roleofuser, and acontentblock containing thetool_resulttype and the following information:tool_use_id: Theidof the tool use request this is a result for.content: The result of the tool, as a string (e.g."content": "15 degrees"), a list of nested content blocks (e.g."content": [{"type": "text", "text": "15 degrees"}]), or a list of document blocks (e.g."content": ["type": "document", "source": {"type": "text", "media_type": "text/plain", "data": "15 degrees"}]). These content blocks can use thetext,image, ordocumenttypes.is_error(optional): Set totrueif the tool execution resulted in an error.
Important formatting requirements:This is correct:If you receive an error like “tool_use ids were found without tool_result blocks immediately after”, check that your tool results are formatted correctly.
- Tool result blocks must immediately follow their corresponding tool use blocks in the message history. You cannot include any messages between the assistant’s tool use message and the user’s tool result message.
- In the user message containing tool results, the tool_result blocks must come FIRST in the content array. Any text must come AFTER all tool results.
Example of successful tool result
Example of successful tool result
JSON
Example of tool result with images
Example of tool result with images
JSON
Example of empty tool result
Example of empty tool result
JSON
Example of tool result with documents
Example of tool result with documents
JSON
Handling results from server tools
Claude executes the tool internally and incorporates the results directly into its response without requiring additional user interaction.Handling the max_tokens stop reason
If Claude’s response is cut off due to hitting the max_tokens limit, and the truncated response contains an incomplete tool use block, you’ll need to retry the request with a higher max_tokens value to get the full tool use.
Handling the pause_turn stop reason
When using server tools like web search, the API may return a pause_turn stop reason, indicating that the API has paused a long-running turn.
Here’s how to handle the pause_turn stop reason:
pause_turn:
- Continue the conversation: Pass the paused response back as-is in a subsequent request to let Claude continue its turn
- Modify if needed: You can optionally modify the content before continuing if you want to interrupt or redirect the conversation
- Preserve tool state: Include the same tools in the continuation request to maintain functionality
Troubleshooting errors
Built-in Error Handling: Tool runner provide automatic error handling for most common scenarios. This section covers manual error handling for advanced use cases.
Tool execution error
Tool execution error
If the tool itself throws an error during execution (e.g. a network error when fetching weather data), you can return the error message in the Claude will then incorporate this error into its response to the user, e.g. “I’m sorry, I was unable to retrieve the current weather because the weather service API is not available. Please try again later.”
content along with "is_error": true:JSON
Invalid tool name
Invalid tool name
If Claude’s attempted use of a tool is invalid (e.g. missing required parameters), it usually means that the there wasn’t enough information for Claude to use the tool correctly. Your best bet during development is to try the request again with more-detailed If a tool request is invalid or missing parameters, Claude will retry 2-3 times with corrections before apologizing to the user.
description values in your tool definitions.However, you can also continue the conversation forward with a tool_result that indicates the error, and Claude will try to use the tool again with the missing information filled in:JSON
<search_quality_reflection> tags
<search_quality_reflection> tags
Server tool errors
Server tool errors
When server tools encounter errors (e.g., network issues with Web Search), Claude will transparently handle these errors and attempt to provide an alternative response or explanation to the user. Unlike client tools, you do not need to handle
is_error results for server tools.For web search specifically, possible error codes include:too_many_requests: Rate limit exceededinvalid_input: Invalid search query parametermax_uses_exceeded: Maximum web search tool uses exceededquery_too_long: Query exceeds maximum lengthunavailable: An internal error occurred
Parallel tool calls not working
Parallel tool calls not working
If Claude isn’t making parallel tool calls when expected, check these common issues:1. Incorrect tool result formattingThe most common issue is formatting tool results incorrectly in the conversation history. This “teaches” Claude to avoid parallel calls.Specifically for parallel tool use:See the general formatting requirements above for other formatting rules.2. Weak promptingDefault prompting may not be sufficient. Use stronger language:3. Measuring parallel tool usageTo verify parallel tool calls are working:4. Model-specific behavior
- ❌ Wrong: Sending separate user messages for each tool result
- ✅ Correct: All tool results must be in a single user message
- Claude Opus 4.1, Opus 4, and Sonnet 4: Excel at parallel tool use with minimal prompting
- Claude Sonnet 3.7: May need stronger prompting or token-efficient tool use
- Claude Haiku: Less likely to use parallel tools without explicit prompting